布隆过滤器算法用于搜索
创始人
2025-07-14 13:01:40
0次

问题: 什么是布隆过滤器?
答案 → 布隆过滤器是一种空间效率高的概率型数据结构。它已经存在了50年。它用于回答这样的问题:这个元素是否在集合中?
问题: 布隆过滤器的实际应用有哪些?
答案 → 布隆过滤器是一种具有许多实际应用的数据结构。它可以在浏览器、网络路由器和数据库中找到,仅举几例。

问题: 可以用布隆过滤器的实际应用场景是什么?
答案 → 布隆过滤器用于回答这个问题:这个元素是否存在于集合中?布隆过滤器会回答“绝对不是”或“可能是”。这个“可能是”的部分使得布隆过滤器具有概率性。
- 可能发生假阳性,即元素实际上不在集合中,但布隆过滤器说它存在。
- 不可能发生假阴性,即元素存在于集合中,但布隆过滤器说它不存在。
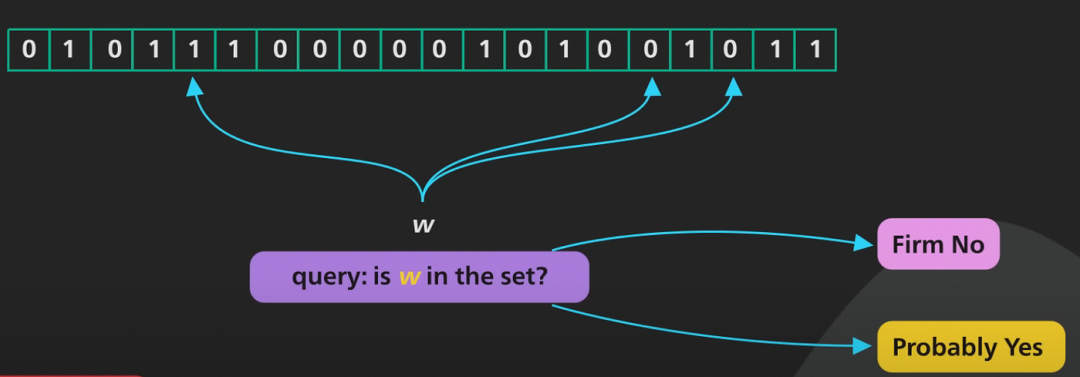
问题: 使用布隆过滤器的权衡是什么?
答案 → 为了有时提供不正确的假阳性答案,布隆过滤器比像哈希表这样的数据结构消耗的内存要少得多,后者能够每次都提供正确的答案。
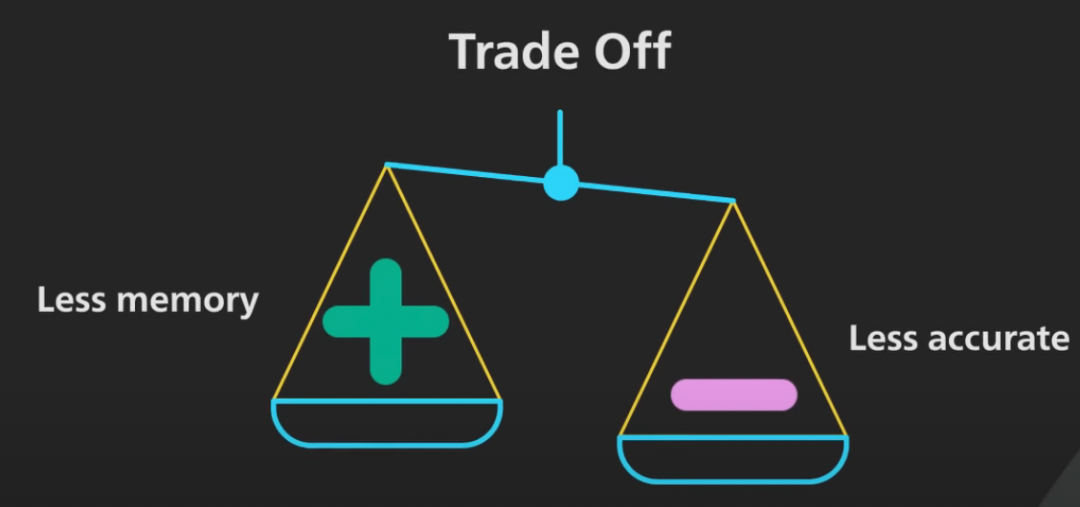
问题: 使用布隆过滤器时我们必须注意什么?
答案 → 如果我们的用例可以容忍一些假阳性并且不能容忍假阴性,那么我们可以选择布隆过滤器。

问题: 布隆过滤器是如何工作的?
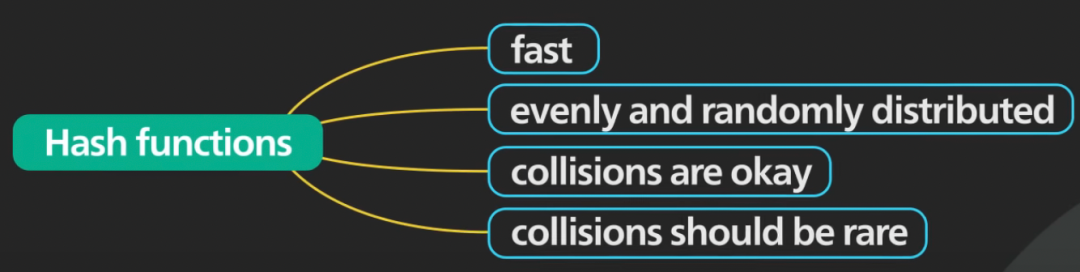
答案 → 布隆过滤器的关键成分是一些好的哈希函数。
- 这些哈希函数应该快速,并且它们应该产生均匀且随机分布的输出。
- 只要碰撞很少,就没关系。
理解 → 一个布隆过滤器是一个大的桶集合,每个桶包含一个比特位,它们都从零开始。假设我们想要跟踪我喜欢的食物。以这个例子:
步骤#1.) 我们从一个大小为10的布隆过滤器开始,标记从0到9:

步骤#2.) 现在,对于每个传入的元素:
- 我们将通过三个不同的哈希函数传递它。
- 每个哈希函数最终会返回一个0到9的范围内的值。
例如,我们想将元素“Ribeye”(一种肉类)放入布隆过滤器。所以,通过三个哈希函数传递这个元素:
- 假设通过哈希函数1传递元素“Ribeye”时,我们得到的值为1。这意味着,索引1处的值会被标记为1。
- 假设通过哈希函数2传递元素“Ribeye”时,我们得到的值为3。这意味着,索引3处的值会被标记为1。
- 假设通过哈希函数3传递元素“Ribeye”时,我们得到的值为4。这意味着,索引4处的值会被标记为1。
步骤#3.) 现在,如果我们想检查“Ribeye”是否在布隆过滤器中:
- 我们再次将“Ribeye”通过相同的三个哈希函数。
- 如果所有三个哈希函数返回的索引位置上的值都是1,那么“Ribeye”可能在布隆过滤器中。
理解 → 由于我们检查的每个索引位置上的值都是1,所以“Ribeye”可能在布隆过滤器中。
这种方法可以快速检查一个元素是否可能存在于一个集合中,同时使用的内存比存储整个集合少得多。
相关内容
热门资讯
PHP新手之PHP入门
PHP是一种易于学习和使用的服务器端脚本语言。只需要很少的编程知识你就能使用PHP建立一个真正交互的...
网络中立的未来 网络中立性是什...
《牛津词典》中对“网络中立”的解释是“电信运营商应秉持的一种原则,即不考虑来源地提供所有内容和应用的...
各种千兆交换机的数据接口类型详...
千兆交换机有很多值得学习的地方,这里我们主要介绍各种千兆交换机的数据接口类型,作为局域网的主要连接设...
粉嫩如何诠释霸道 东芝M805...
“霸道粉”是个什么玩意东芝M805拿过来的时候,笔者扑哧笑了,不是笑这款笔记本,而是笑这款产品的颜色...
什么是大数据安全 什么是大数据...
在《为什么需要大数据安全分析》一文中,我们已经阐述了一个重要观点,即:安全要素信息呈现出大数据的特征...
如何利用交换机和端口设置来管理...
在网络管理中,总是有些人让管理员头疼。下面我们就将介绍一下一个网管员利用交换机以及端口设置等来进行D...
全面诠释网络负载均衡
负载均衡的出现大大缓解了服务器的压力,更是有效的利用了资源,提高了效率。那么我们现在来说一下网络负载...
如何允许远程连接到MySQL数...
[[277004]]【51CTO.com快译】默认情况下,MySQL服务器仅侦听来自localhos...
30分钟搞定iOS自定义相机
最近公司的项目中用到了相机,由于不用系统的相机,UI给的相机切图,必须自定义才可以。就花时间简单研究...
Intel将Moblin社区控...
本周二,非营利机构Linux基金会宣布,他们将担负起Moblin社区的管理工作,而这之前,Mobli...