两亿参数时序模型替代LLM?谷歌突破性研究被批「犯新手错误」
最近,谷歌的一篇论文在 X 等社交媒体平台上引发了一些争议。
这篇论文的标题是「A decoder-only foundation model for time-series forecasting(用于时间序列预测的仅解码器基础模型)」。

简而言之,时间序列预测就是通过分析历史数据的变化趋势和模式,来预测未来的数据变化。这类技术在气象预报、交通流量预测、商业销售等领域有着广泛的应用。例如,在零售业中,提高需求预测的准确性可以有效降低库存成本并增加收入。
近年来,深度学习模型已成为预测丰富的多变量时间序列数据的流行方法,因为它们已被证明在各种环境中表现出色。
但是,这些模型也面临一些挑战:大多数深度学习架构需要漫长而复杂的训练和验证周期,急需一个开箱即用的基础模型来缩短这一周期。
谷歌的新论文就是为了解决这一问题而诞生的。在论文中,他们提出了一个用于时间序列预测的仅解码器基础模型 ——TimesFM。这是一个在 1000 亿个真实世界时间点的大型时间序列语料库上预训练的单一预测模型。与最新的大型语言模型相比,TimesFM 要小得多(仅 200M 参数)。但他们发现,即使在这样的规模下,它在不同领域和时间粒度的各种未见数据集上的零样本性能也接近于在这些数据集上显式训练的 SOTA 监督方法。
这个想法看起来很有前景,有人评价说,「TimesFM 证明了预训练大型时间序列语料库的力量。它在各种公开的基准测试中展示的零样本性能真的令人称奇」。

但也有人对其采用的评估方法和基准产生了质疑,毕业于伦敦大学皇家霍洛威学院的 Valery Manokhin 博士指出,论文作者犯了一些「新手错误」,还采用了一些「欺骗性」的基准。

事情到底是怎么回事?我们先来看看谷歌的这篇论文写了什么。
被质疑的论文写了什么?
上周五,谷歌 AI 专门用博客介绍了这一研究。

我们目前常见的大语言模型(LLM)通常在训练时仅用解码器,过程涉及三个步骤。首先,文本被分解为称为标记的子词 ——token。然后,token 被输入到堆叠的因果 transformer 层中,这些层会生成与每个输入 token 相对应的输出。最后,第 i 个 token 对应的输出总结了之前 token 的所有信息并预测第 (i+1) 个 token。
在推理过程中,LLM 一次生成一个 token 的输出。例如,当提示「What is the capital of France?」时,它可能会生成 token「The」,然后以「What is the capital of France? The」为条件。生成下一个标记「capital」,依此类推,直到生成完整的答案:「The capital of France is Paris」。
谷歌认为,时间序列预测的基础模型可以适应可变的上下文(我们观察到的内容)和范围(我们查询模型预测的内容)长度,同时具有足够的能力对大型预训练数据集中的所有模式进行编码。
与 LLM 类似,我们可以使用堆叠 transformer 层(自注意力层和前馈层)作为 TimesFM 模型的主要构建块。在时间序列预测的背景下,将 patch(一组连续的时间点)视为最近长期预测工作的 token。随后,任务是根据堆叠 transformer 层末尾的第 i 个输出来预测第 (i+1) 个时间点 patch。
在论文《A decoder-only foundation model for time-series forecasting》中,谷歌研究人员尝试设计了一个时间序列基础模型,在零样本(zero-shot)任务上取得了不错的效果:

论文链接:https://arxiv.org/abs/2310.10688
该研究中,研究者设计了一种用于预测的时间序列基础模型 TimesFM,其在各种公共数据集上的 zero-shot 能力都接近于目前业内的顶尖水平。此模型是一种在包含真实世界和合成数据的大型时间序列语料库上进行预训练的,修补解码器式注意力模型,参数只有两亿。
谷歌表示,对于首次遇见的各种预测数据集进行的实验表明,该模型可以在不同领域、预测范围和时间粒度上产生准确的零样本预测。
时间序列的基础模型可以大幅减少训练数据和计算需求,为应用端带来很多好处。不过,时间序列推理的基础模型是否是一种可行的思路,人们还未有定论,首先与 NLP 不同,时间序列没有明确定义的词汇或语法。此外,新模型需要支持具有不同历史长度(上下文)、预测长度(范围)和时间粒度的预测。此外,与用于预训练语言模型的大量公共文本数据不同,大型时间序列数据集并不容易构建。
谷歌表示,尽管存在这些问题,他们还是提供了证据来肯定地回答上述问题。

图 1:训练过程中的模型架构。其中显示了可以分解为输入补丁的特定长度的输入时间序列。
它与常规的语言模型有几个关键的区别。首先,我们需要一个具有残差连接的多层感知器块,将时间序列 patch 转换为可以与位置编码(PE)一起输入到 Transformer 层的 token。为此,谷歌使用了与他们之前的长期预测工作类似的残差块。其次,在另一端,来自堆叠 Transformer 的输出 token 可用于预测比输入 patch 长度更长的后续时间点的长度,即输出 patch 长度可以大于输入 patch 长度。
谷歌研究者认为,即使基线针对每个特定任务进行了专门训练或调整,TimesFM 的单个预训练模型也可以在基准测试中接近或超过基线模型的性能。

图 2:新方法与常规方法在三组数据集上的平均性能对比,指标越低越好。谷歌表示,在基线测试中,只有 TimesFM 和 llmtime 是零样本。
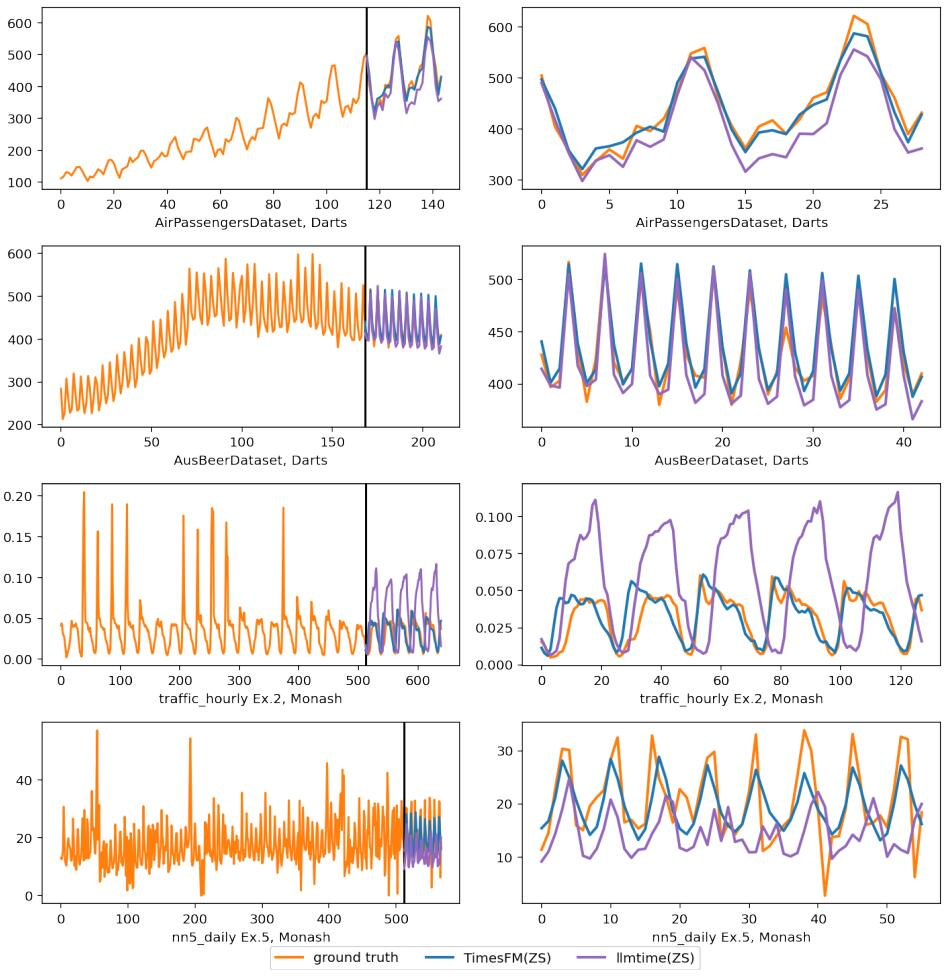
图 6:在 Darts 和 Monash 数据集上的推理可视化。右侧的图放大了左侧的预测部分。
看起来,从背景到思路,方法到测试的一套流程都已走完,事情就顺理成章了,谷歌还计划在今年内通过 Google Cloud Vertex AI 向外部客户提供此模型。
哪知道论文竟引起了争议。
Valery Manokhin 提出了哪些质疑?
对论文评估方法和所选基准提出质疑的是机器学习博士 Valery Manokhin。他的研究领域包括概率预测、符合预测、机器学习、深度学习、人工神经网络、人工智能和数据挖掘等。
他指出,首先,论文中使用图表(特别是图 6)以视觉方式展示模型性能是一个初学者的错误。Christoph Bergmeir 和 Hansika Hewamalage 在其教程《数据科学家的预测评估:常见陷阱和最佳实践(Forecast Evaluation for Data Scientists: Common Pitfalls and Best Practices)》中明确指出,生成预测的视觉吸引力或其可能性不是评价预测的好标准。

接下来,Valery Manokhin 提到,谷歌的作者使用了一种标准策略来美化他们的「基础模型」性能,即选择那些可以被传统模型非常容易且几乎完美地拟合的经典数据集(如非常老的航空乘客数据)。而且,谷歌的作者没有选择传统模型作为基准进行比较,而是选择了另一个表现不佳的模型(llmtime)作为对照。


针对 Valery 提出的质疑,谷歌研究院的 Rajat Sen(论文作者之一)在帖子下面给出了回应。首先,他指出,批评者仅关注了论文中一个关于航空乘客数据集的示例,并错误地认为这是他们唯一展示的性能数据。作者澄清说他们实际上在多个数据集(Monash、Darts 和 ETT)上报告了模型的性能。

而且,作者强调,他们并没有通过视觉方式来评估模型性能。图 6 仅仅是为了示例目的,而综合性能是在图 2 中报告的。


作者明确指出,他们没有选择性挑选结果来美化模型性能。在图 2 中,他们公正地展示了一些监督学习模型可能比他们的模型表现得更好,但他们的模型是一个零样本模型,这是一个重要的优势。
但 Valery Manokhin 随后又指出,在 Monash 数据集上,谷歌的 TimesFM 落后于其他模型。

对此,Rajat Sen 指出,Valery Manokhin 忽略了一个很重要的点:TimesFM 的表现优于 Monash 上的很多既有基线,但最重要的是,这些基线是单独在这些数据集上「训练」的,而 TimesFM 是「零样本」预测的。

随后,二人的争论又集中到了文中的一句话上。作者在论文的引入部分写道,「在一些预测竞赛,如 M5 竞赛(M5 “Accuracy” competition)和 IARAI Traffic4cast 竞赛中,几乎所有获胜的解决方案都是基于深度神经网络的。」Valery Manokhin 认为这句话具有误导性。


对此,Rajat Sen 表示,这不是文章的核心论点,还有进一步讨论的空间。

如今,二人的争论还在 X 平台上持续更新,感兴趣的读者可以前去观战。