Python入门必备:细讲Python推导式
由于Python的良好生态,很多时候我们的程序只是通过调用别人写好的方法即可实现功能。
不过,很多时候我们还是需要处理序列。不管是入门中还是早已入门的小伙伴,对于处理序列毫无疑问会选择用for循环。但在Python中还有一种更高效更简洁的处理序列方式——推导式。本文详细探讨关于推导式的细节。

for循环有啥不好,非要学推导式?
我们来看一个例子,如何把一个数值列表中大于0的数值筛选出来。下图给出for循环的做法
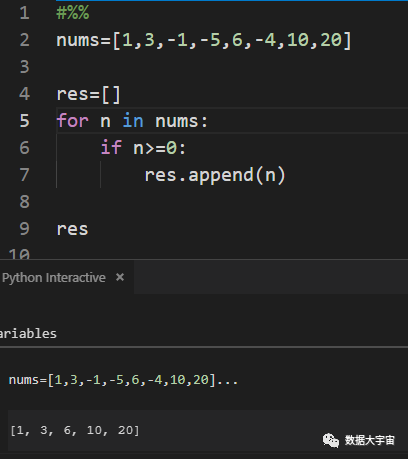
可以看到for循环还是妥妥地把问题解决,代码并不复杂。
分析代码与原问题的表达对应关系:
- 行5,表达从数值列表取出数值。
- 行6,表达"大于0的数值筛选出来"
- 但原问题没有提及到创建一个用于保存结果的列表和如何把结果加入结果列表。
- 上面的代码中的行4与行7,都是多余的动作。
是时候让推导式出场了
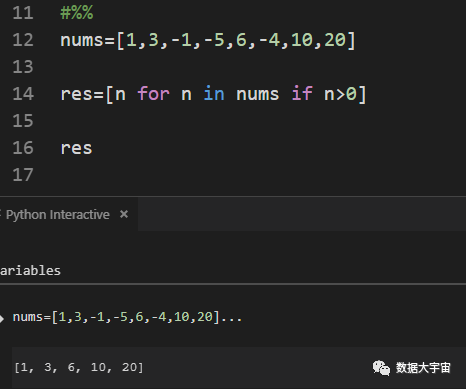
上图是一种比较"官方"的写法,把整个推导式写到一行里,我更喜欢下图的写法。
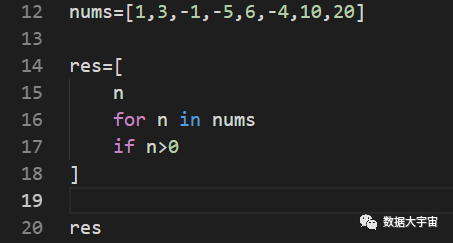
这就是列表推导式,很简单吧。看起来其实与之前的for循环写法差不多。但推导式有以下好处::
- 不需要像for循环那样,先定义一个列表,然后在循环中编写如何把结果放入列表的代码。
- 表达更为清晰了,推导式的每个部分都与原问题的表达一一对应。
- 行15,表达了 我要把什么样的东西放入结果中,这里只有一个n,表示符合要求的数值。
- 行16与行17与之前for循环分析是一致。注意看,这里不再需要写冒号了。
- 推导式的外面用一个[]包围着,表示结果是一个列表。
- 推导式的性能更好。在序列的数据量不大的情况下推导式的性能优势不会太明显,如果序列的元素数量成千上万,那么推导式比for形式性能通常优胜2倍以上。
通过对比学习推导式
觉得怎么样,推导式是不是语义表达好的同时性能又高呢。下面通过与for循环形式对比来学习推导式的写法。
图中左边是for循环,右边是推导式:
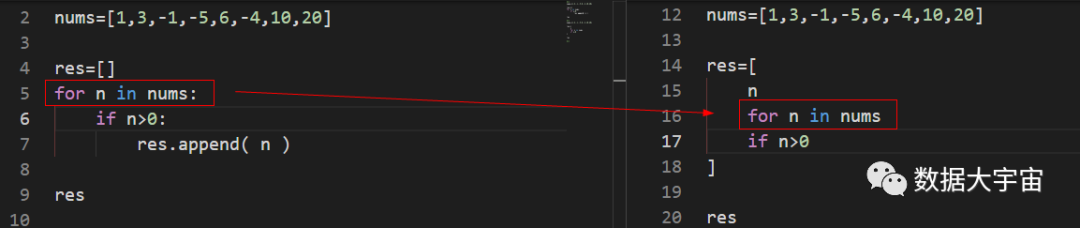
红框部分表示遍历序列,可以看到两者形式一样,但注意,推导式不需要在最后写冒号:
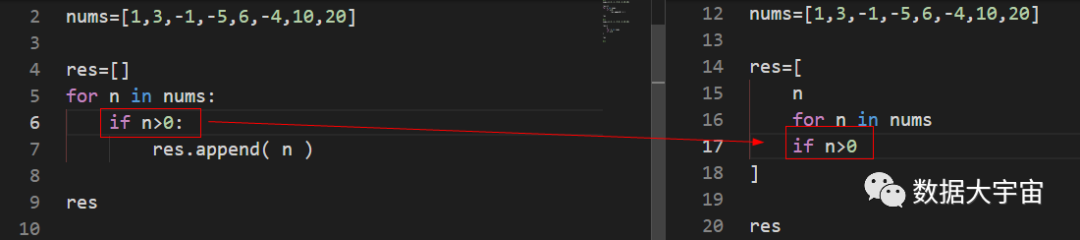
同样地,上图红框表示如何判断每个元素,这里表示过滤的条件。
我们可以写各种各样复杂的判断条件。
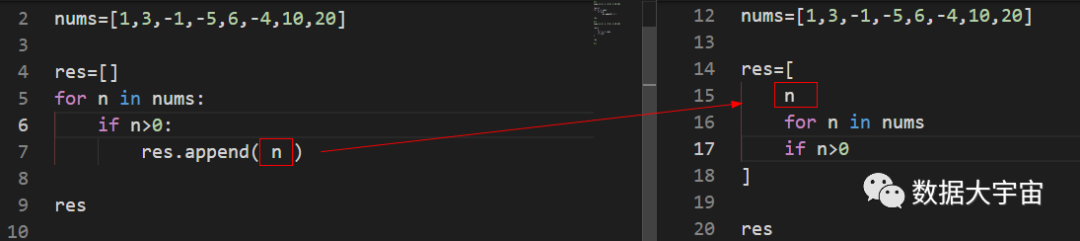
上图红框是推导式最后一部分,他决定了输出结果
比如说,如果希望每个输出值是原来的两倍,我们就可以写 n*2
结果可以是各种各样的类型,比如红框部分如果写 f'值:{n}',那么结果就是一系列的字符串。
更进一步
我们来看一个稍微复杂点的例子。
假设我们有多个文件,每个文件都有多行数值(都是整数),行数不确定。如图:

现在需要把多个这样的文件的所有数值拿出来,然后把小于50的数值筛选出来作为结果,并且标注每个数值的来源文件。
下图是基本数据的定义:
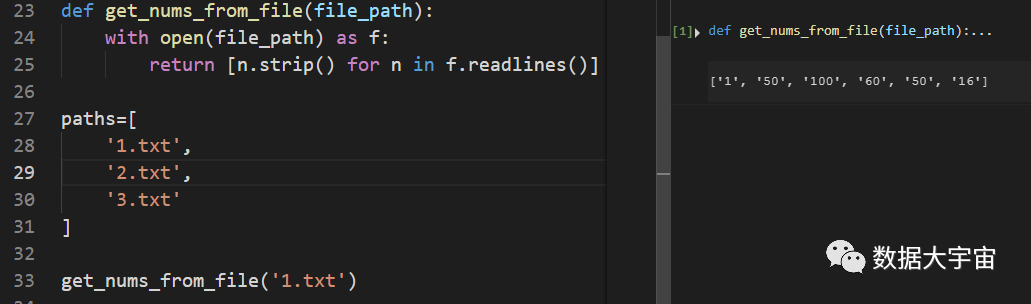
方法 get_nums_from_file 不是这里的重点,我们只需要知道,给他一个文本路径,他会读取文件中的每行的整数,以返回一个整数列表
这个问题可以描述为"列表中的元素还可以提取出一个列表",这样的情况下同样可以用推导式。如下:
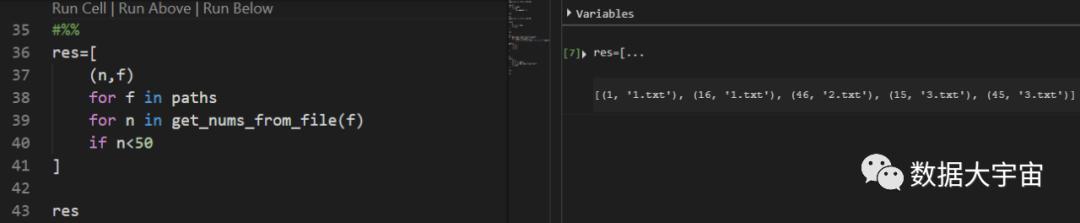
- 其实与普通的for循环嵌套是差不多的套路
- 行38,首先遍历paths列表
- 行39,在上一个循环中获取文件中的整数列表再次遍历这个整数列表
- 行40,对应原问题的筛选条件。
- 行37,这里可以使用下方两个for的变量f和n,因此可以轻而易举找到每个数值的来源
有时候不应该强行使用推导式
我们很容易犯的一个错误是,手上拿着一个锤子,看啥都认为是钉子,更何况拿着的是一个雷神之锤。
推导式简洁又高效的好处,很容易让人着迷于使用他来解决一切的集合处理问题。我们接着上面的需求来说明。
现在需求不仅仅过滤小于50的数值,而是取出"小于所在文件的所有数值的平均",并且结果需要显示该文件的平均值。
下面是推导式的解决方法:
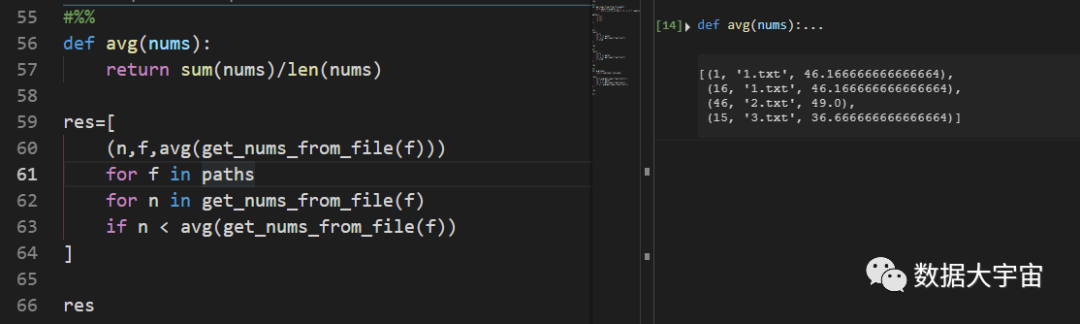
推导式最大的问题在于无法在过程中建立临时变量
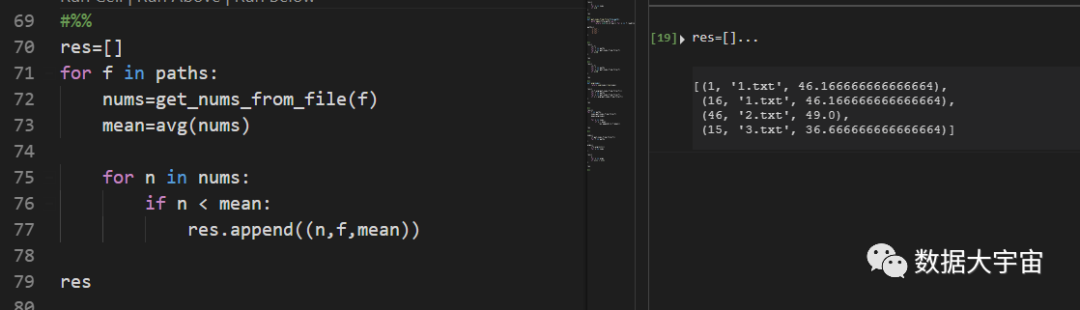
这个需求下,由于没法用临时变量保存一个文件的平均值,因此导致多次求平均,不仅代码结构乱,而且效率还很低。
这时候老老实实使用for循环是个很好的选择。如下:
未来,推导式可能的进化
Python的推导式其实来源于函数式编程中的思想,目前市面上的几门面向对象编程语言都加入了相关方面的语法,未来Python的推导式可能会参考他们从而改进自身的推导式语法。如图为C#的Linq,特点是他允许在过程中定义临时变量。
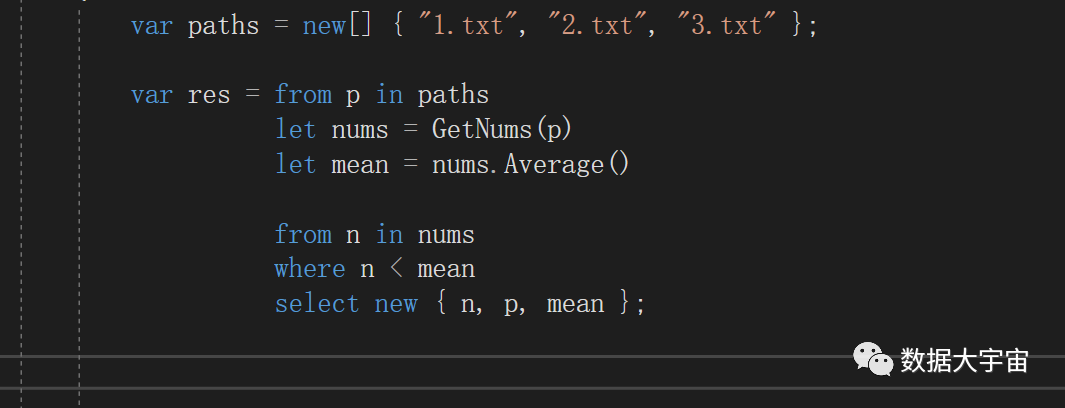
可以看到,如果Python的推导式加入这样的语法功能,那么本文说的推导式的缺点就不再出现。Python的推导式在未来的进化值得期待。
小结
- 在处理序列时,推导式是一个高效简洁的方式
- 当需求需要在循环中创建各种临时的状态数据时,推导式就不再适合处理。建议考虑使用for循环。
在Python中,推导式很多时候被当作是否熟悉Python的标志之一,同时推导式也存在许多争议,我们应该清楚了解推导式再谈如何应用,毕竟任何技术都必需在适当的地方才能发挥最大的作用。
你已经学会了推导式了吗?平时使用for循环比较多还是推导式比较多?
上一篇:C 模板背后的黑箱操作:编译器
下一篇:Netty入门实践:模拟IM聊天