Andrej Karpathy:大模型有内存限制,这个妙招挺好用
「如今,LLM(大语言模型)并不是单点突破的 —— 而是需要多个重要组件有效协同工作的系统。Speculative decoding 是帮助我们从系统角度思考的一个很好的例子。」爱丁堡大学博士生符尧表示道。

符尧上述观点评论的是特斯拉前 AI 总监、年初重回 OpenAI 的 Andrej Karpathy 刚刚发布的一条推特。
人形机器人公司 1X Technologies 的 AI 副总裁 Eric Jang 评价道:「Karpathy 很好的解释了 LLM 的 speculative execution。其他自回归模型可能会以类似的方式加速。连续(扩散)模型可能从 K 步中获益较少(可能在第 1 步后偏离猜测),但可以将其应用于 VQ-latents 的离散代码。」
看完上述评价,我们大概也了解了,Karpathy 说的「Speculative execution」,这是优化技术的一类,采用这个技术的计算机系统会根据现有信息,利用空转时间提前执行一些将来可能用得上,也可能用不上的指令。如果指令执行完成后发现用不上,系统会抛弃计算结果,并回退执行期间造成的副作用(如缓存)。
为了让大家更好的理解 Karpathy 的内容。我们先介绍一下「Speculative decoding」方法,对后续理解更加有益,其主要用于加速大模型的推理。据了解,GPT-4 泄密报告也提到了 OpenAI 线上模型推理使用了它(不确定是否 100%)。
关于「Speculative decoding」,已有几篇重要文献可供参考,这也是 Karpathy 为了写这则推特所参考的论文,包括谷歌今年 1 月发表的论文《Fast Inference from Transformers via Speculative Decoding》、DeepMind 今年 2 月发表的论文《Accelerating Large Language Model Decoding with Speculative Sampling》,以及谷歌等机构 2018 年的论文《Blockwise Parallel Decoding for Deep Autoregressive Models 》 。
简单来说,「Speculative decoding」使用两个模型:一个是原始目标模型称为大模型,另一个是比原始模型小得多的近似模型称为小模型。主要思想是先让小模型提前解码多个 token 进行猜测,并将它们作为单个 batch 输入到一个大模型中进行审核修正,其效果和直接用大模型解码等价。如果小模型猜测的不准确,那么大型模型会放弃小模型预测的 token,继续使用大型模型进行解码。
由于小模型计算量小,从而大大减少了内存访问需求。
介绍完「Speculative decoding」,我们再回到 Karpathy 的推特。Karpathy 是针对下面内容回复的。
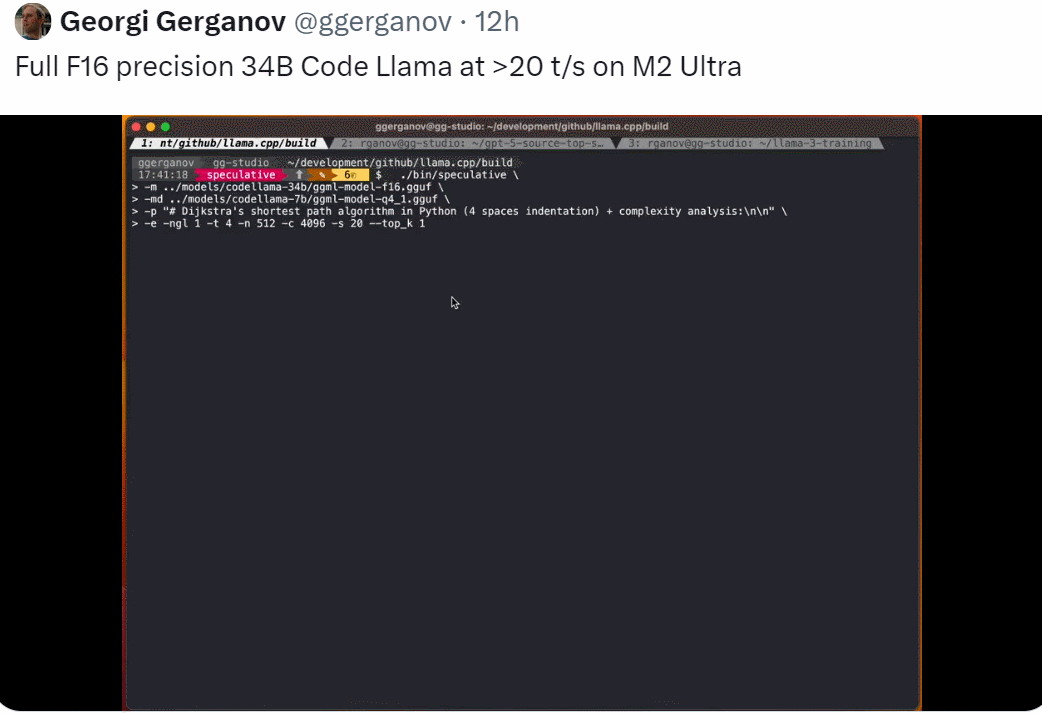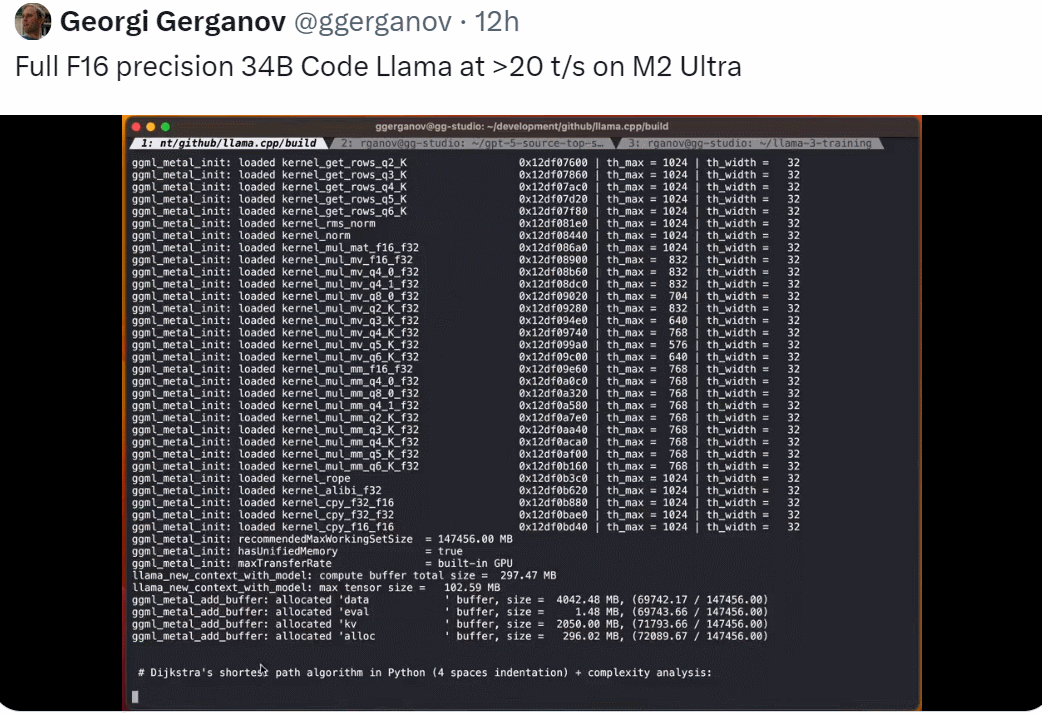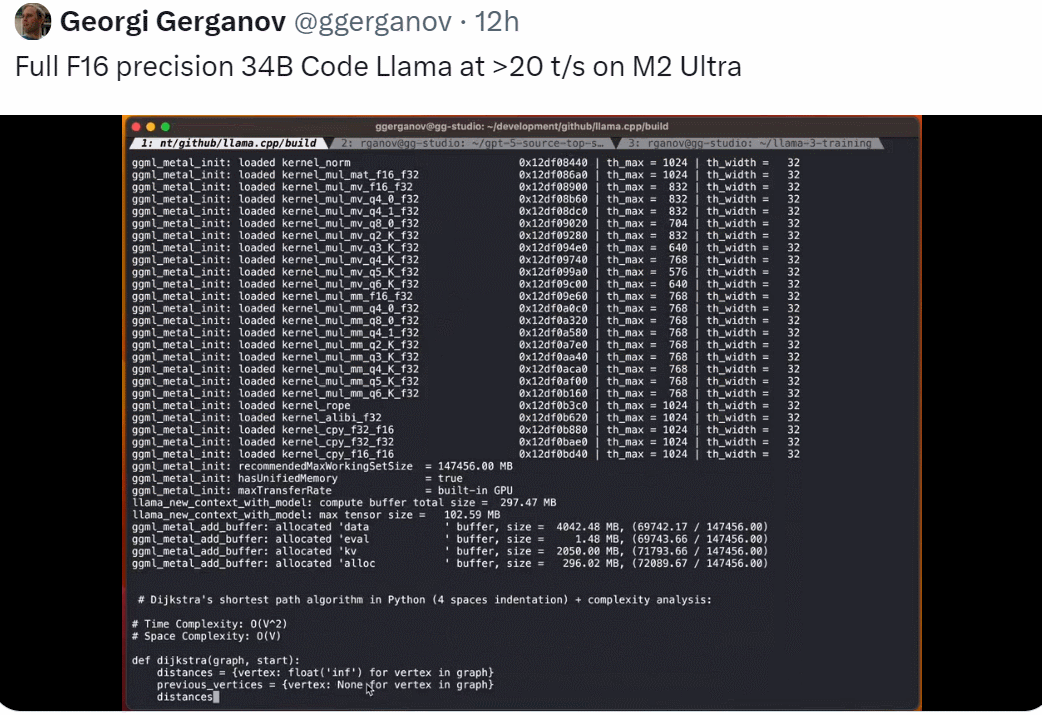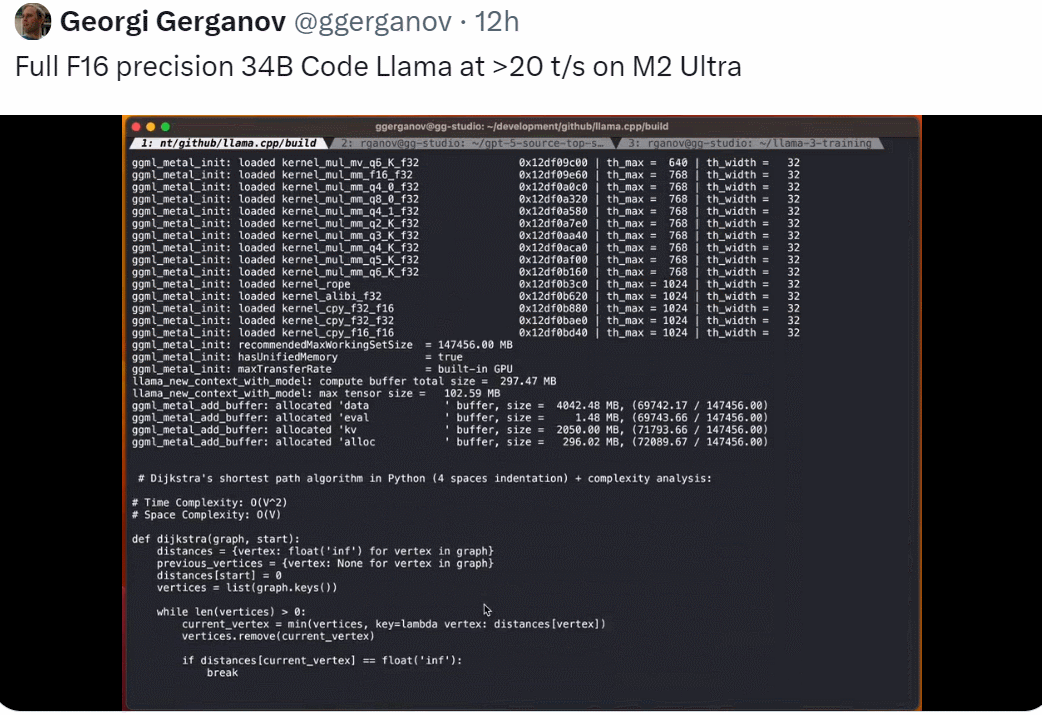
Karpathy 表示:对于 LLM 来说,「Speculative execution」 是一种极好的推理 — 时间优化方法。
它取决于以下方面:在单个输入 token 上分发 LLM 所花费的时间与在批处理中分发 K 个输入 token 所花费的时间一样多。产生这样的原因是因为采样严重受内存限制:模型运行时的大部分工作不是在做计算,而是从 VRAM 读取 transformer 的权重到片上缓存进行处理。如果你要做的工作是来读取这些权值,你可以把它们应用到一整批输入向量上。
但是我们不能一次性采样一批 K 个 token,因为每 N 个 token 都取决于我们在第 N-1 步采样的 token。由于存在串行依赖性,因此基线实现只是从左到右逐一进行。
现在最聪明的想法是使用一个小而便宜的草稿模型(draft model),先生成 K 个 token 候选序列,即一个「草稿」。然后用大模型批量的将输入组合在一起。速度几乎与仅输入一个 token 一样快。接着从左到右遍历模型和样本 token 预测的 logits。任何与「草稿」一致的样本都允许立即跳到下一个 token。如果存在分歧,那么就丢弃「草稿」并承担一些一次性工作的成本(对「草稿」进行采样并为所有后续 token 进行前向传递)。
这种方法起作用的原因在于,很多「草稿」token 都会被接受,因为它们很容易,所以即使是更小的草稿模型也能得到它们。当这些简单的 token 被接受时,我们会跳过这些部分。大模型不同意的 hard token 会回落到原始速度,但由于一些额外的工作,实际上速度会慢一些。
Karpathy 表示,这个奇怪的技巧之所以有效,是因为 LLM 在推理时受到内存限制,在对单个序列进行采样的 batch size=1 设置中,很大一部分本地 LLM 用例都属于这种情况。因为大多数 token 都很「简单」。
参考链接:https://twitter.com/karpathy/status/1697318534555336961
下一篇:边缘计算:将计算推向网络边缘