把LangChain跑起来的三个方法
创始人
2025-06-28 08:01:38
0次
使用LangChain开发LLM应用时,需要机器进行GLM部署,好多同学第一步就被劝退了,那么如何绕过这个步骤先学习LLM模型的应用,对Langchain进行快速上手?本片讲解3个把LangChain跑起来的方法,如有错误欢迎纠正。
Langchain官方文档地址:https://python.langchain.com/
基础功能
LLM 调用
- 支持多种模型接口,比如 OpenAI、HuggingFace、AzureOpenAI …
- Fake LLM,用于测试
- 缓存的支持,比如 in-mem(内存)、SQLite、Redis、SQL
- 用量记录
- 支持流模式(就是一个字一个字的返回,类似打字效果)
Prompt管理,支持各种自定义模板
拥有大量的文档加载器,比如 Email、Markdown、PDF、Youtube …
对索引的支持
- 文档分割器
- 向量化
- 对接向量存储与搜索,比如 Chroma、Pinecone、Qdrand
Chains
- LLMChain
- 各种工具Chain
- LangChainHub
详细地址可参考:https://www.langchain.cn/t/topic/35
测试Langchain工程的3个方法:
1 使用Langchian提供的FakeListLLM
为了节约时间,直接上代码
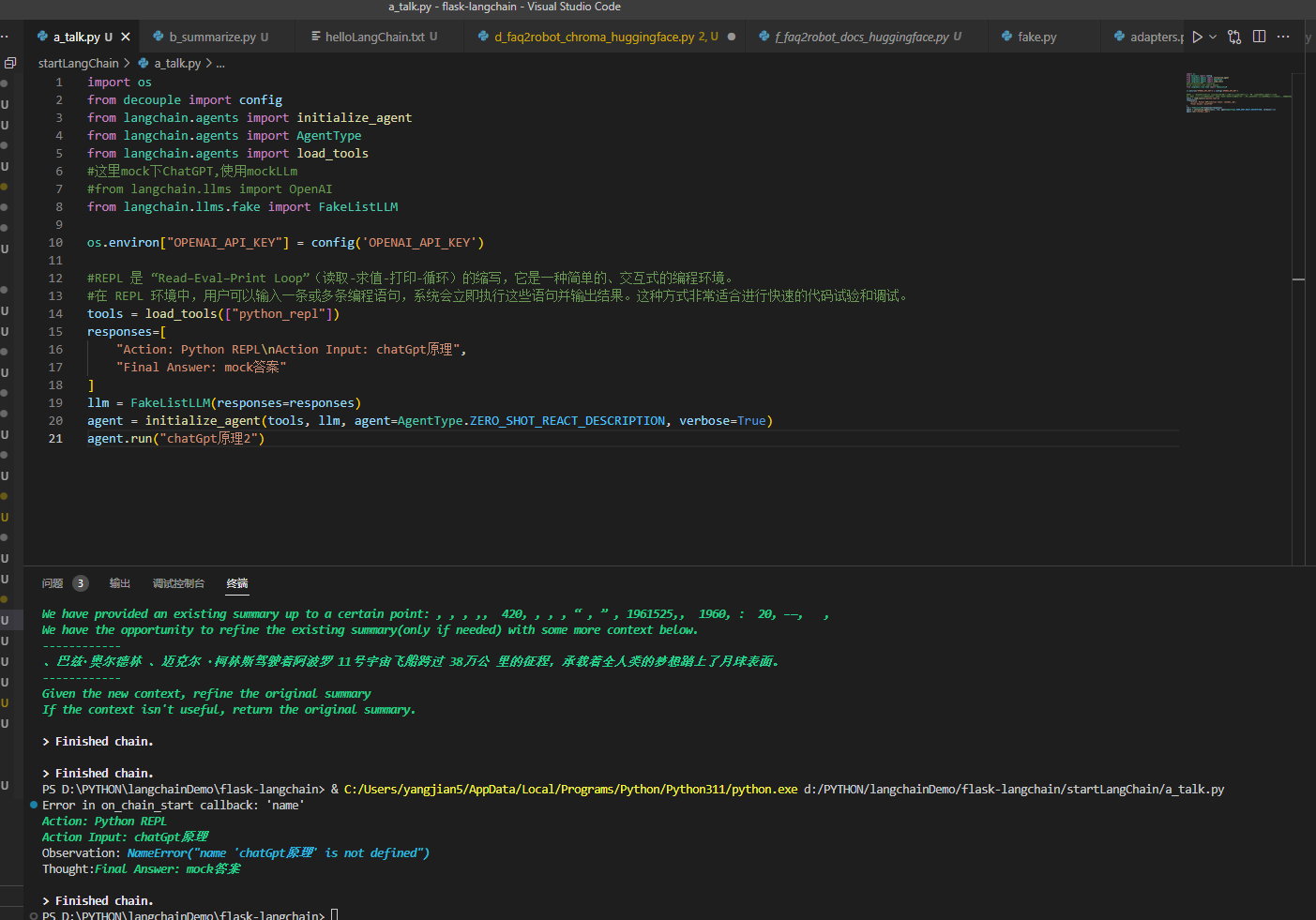
import os
from decouple import config
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.agents import load_tools这里mock下ChatGPT,使用mockLLm
#from langchain.llms import OpenAI
from langchain.llms.fake import FakeListLLM
os.environ["OPENAI_API_KEY"] = config('OPENAI_API_KEY')REPL 是 “Read–Eval–Print Loop”(读取-求值-打印-循环)的缩写,它是一种简单的、交互式的编程环境。
在 REPL 环境中,用户可以输入一条或多条编程语句,系统会立即执行这些语句并输出结果。这种方式非常适合进行快速的代码试验和调试。
tools = load_tools(["python_repl"])
responses=[
"Action: Python REPL\nAction Input: chatGpt原理",
"Final Answer: mock答案"
]
llm = FakeListLLM(responses=responses)
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("chatGpt原理2")2 使用Langchian提供的HumanInputLLM,访问维基百科查询
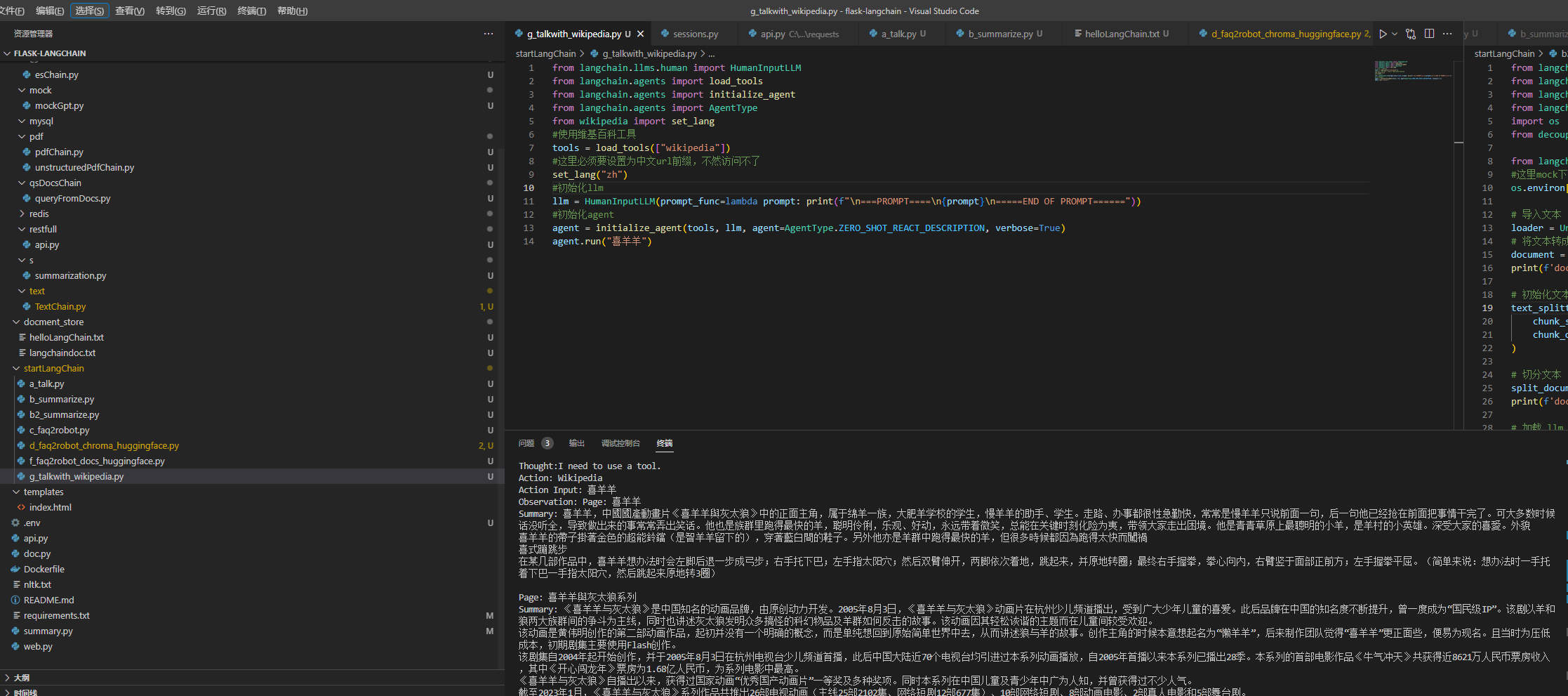
from langchain.llms.human import HumanInputLLM
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from wikipedia import set_lang使用维基百科工具
tools = load_tools(["wikipedia"])这里必须要设置为中文url前缀,不然访问不了
set_lang("zh")初始化LLM
llm = HumanInputLLM(prompt_func=lambda prompt: print(f"\n===PROMPT====\n{prompt}\n=====END OF PROMPT======"))初始化agent
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
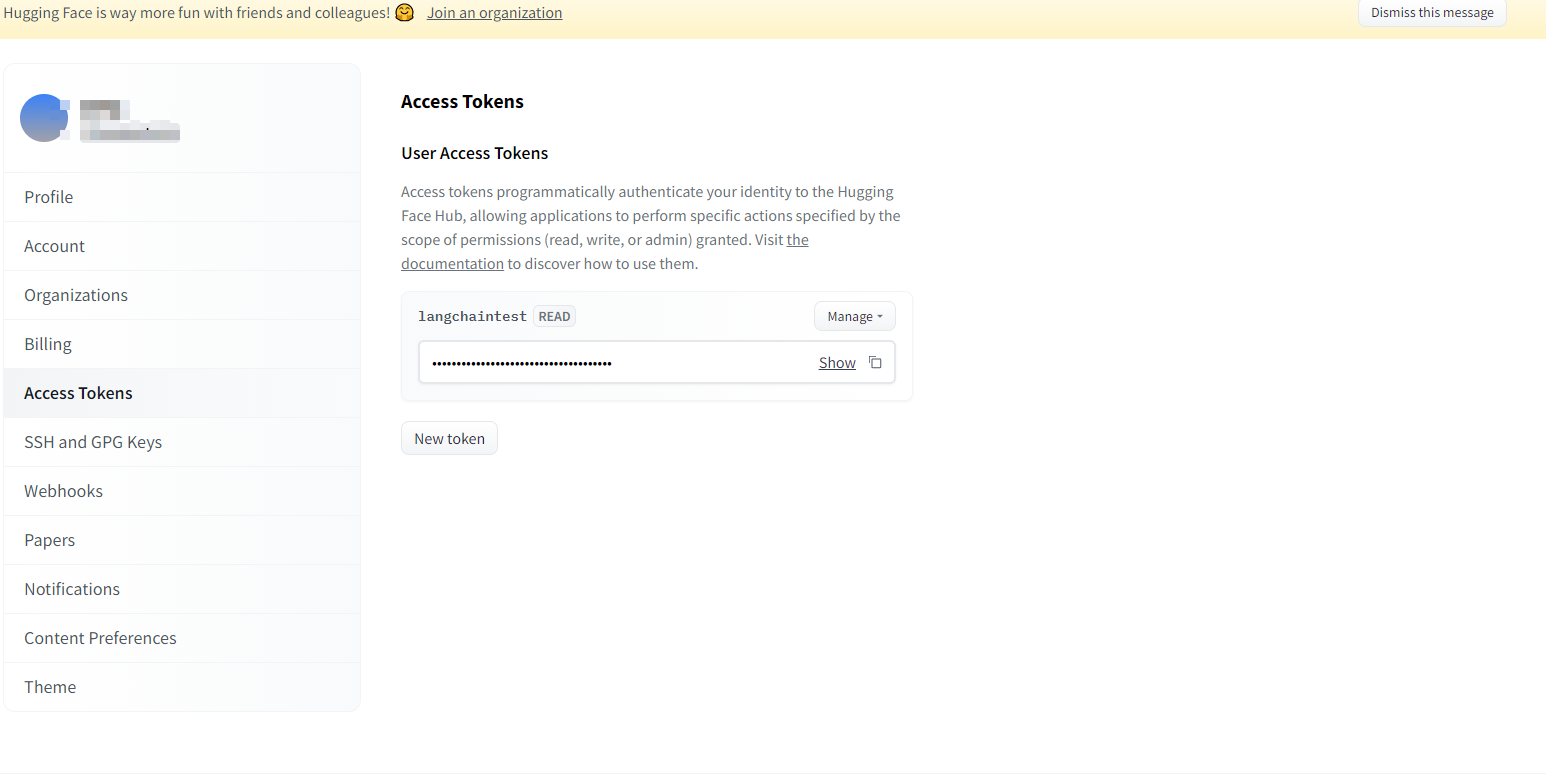
agent.run("喜羊羊")3 使用huggingfacehttps://huggingface.co/docs
1)注册账号
2)创建Access Tokens
Demo: 使用模型对文档进行摘要
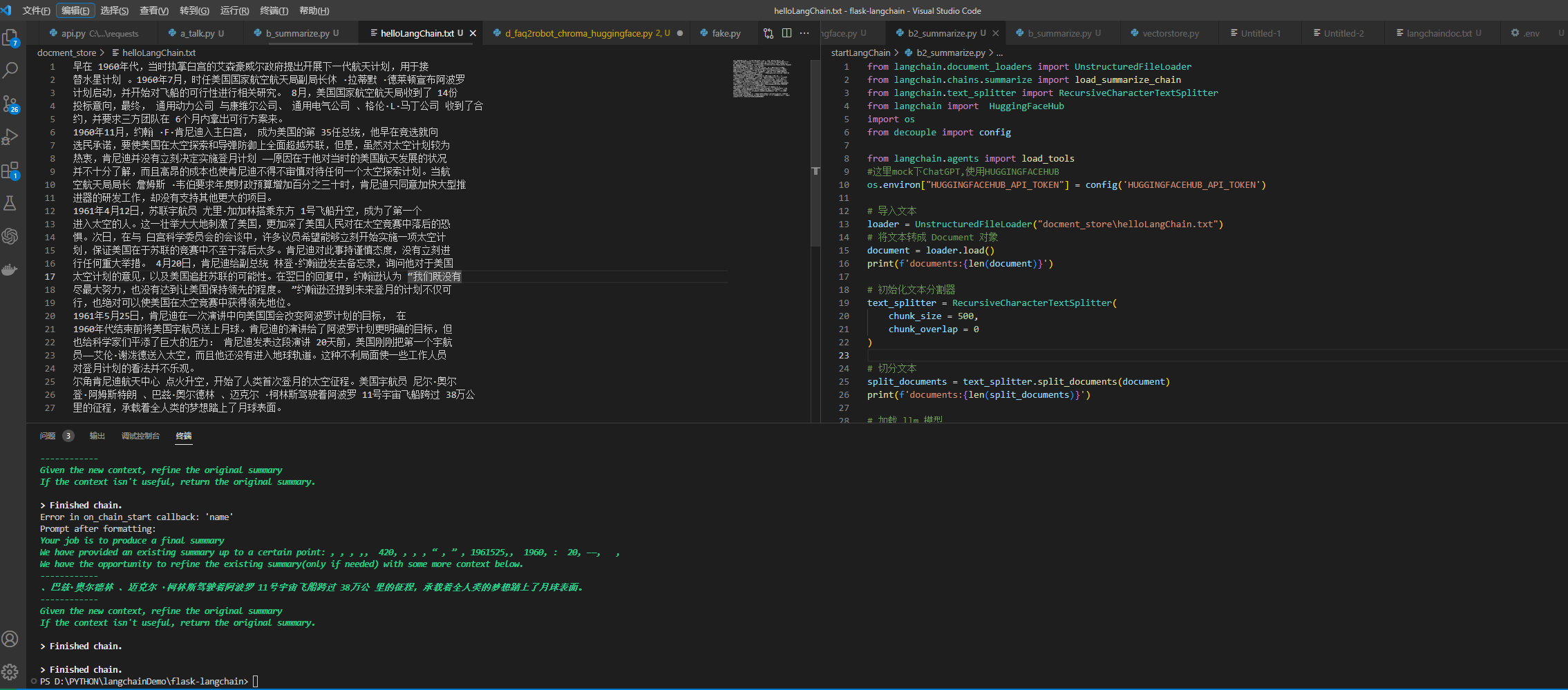
from langchain.document_loaders import UnstructuredFileLoader
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain import HuggingFaceHub
import os
from decouple import config
from langchain.agents import load_tools这里mock下ChatGPT,使用HUGGINGFACEHUB
os.environ["HUGGINGFACEHUB_API_TOKEN"] = config('HUGGINGFACEHUB_API_TOKEN')导入文本
loader = UnstructuredFileLoader("docment_store\helloLangChain.txt")将文本转成 Document 对象
document = loader.load()
print(f'documents:{len(document)}')初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 500,
chunk_overlap = 0
)切分文本
split_documents = text_splitter.split_documents(document)
print(f'documents:{len(split_documents)}')加载 LLM 模型
overal_temperature = 0.1
flan_t5xxl = HuggingFaceHub(repo_id="google/flan-t5-xxl",
model_kwargs={"temperature":overal_temperature,
"max_new_tokens":200}
)
llm = flan_t5xxl
tools = load_tools(["llm-math"], llm=llm)创建总结链
chain = load_summarize_chain(llm, chain_type="refine", verbose=True)执行总结链
chain.run(split_documents)作者:京东科技 杨建
来源:京东云开发者社区
相关内容
热门资讯
如何允许远程连接到MySQL数...
[[277004]]【51CTO.com快译】默认情况下,MySQL服务器仅侦听来自localhos...
如何利用交换机和端口设置来管理...
在网络管理中,总是有些人让管理员头疼。下面我们就将介绍一下一个网管员利用交换机以及端口设置等来进行D...
施耐德电气数据中心整体解决方案...
近日,全球能效管理专家施耐德电气正式启动大型体验活动“能效中国行——2012卡车巡展”,作为该活动的...
20个非常棒的扁平设计免费资源
Apple设备的平面图标PSD免费平板UI 平板UI套件24平图标Freen平板UI套件PSD径向平...
德国电信门户网站可实时显示全球...
德国电信周三推出一个门户网站,直观地实时提供其安装在全球各地的传感器网络检测到的网络攻击状况。该网站...
为啥国人偏爱 Mybatis,...
关于 SQL 和 ORM 的争论,永远都不会终止,我也一直在思考这个问题。昨天又跟群里的小伙伴进行...
《非诚勿扰》红人闫凤娇被曝厕所...
【51CTO.com 综合消息360安全专家提醒说,“闫凤娇”、“非诚勿扰”已经被黑客盯上成为了“木...
2012年第四季度互联网状况报...
[[71653]] 北京时间4月25日消息,据国外媒体报道,全球知名的云平台公司Akamai Te...