Linux内存管理那些事儿
自冯诺伊曼已来,计算机都是采用程序存储架构。
什么是程序存储架构?简单来说就是把用来运行的程序也当做数据一样存储在计算机中。现在听起来这么简单的一个思想,***提出却是了不起的贡献:里面包含了哥德尔精致的集合悖论和图灵美妙的图灵机设想。最早的计算机器仅内含固定用途的程序。现代的某些计算机依然维持这样的设计方式,通常是为了简化或教育目的。例如一个计算器仅有固定的数学计算程序,它不能拿来当作文字处理软件,更不能拿来玩游戏。若想要改变此机器的程序,你必须更改线路、更改结构甚至重新设计此机器。当然最早的计算机并没有设计的那么可编程化。当时所谓的“重写程序”很可能指的是纸笔设计程序步骤,接着制订工程细节,再施工将机器的电路配线或结构改变。而程序存储型电脑的概念改变了这一切。借由创造一组指令集结构,并将所谓的运算转化成一串程序指令的运行细节,让此机器更有弹性。借着将指令当成一种特别类型的静态数据,一台存储程序型电脑可轻易改变其程序,并在程控下改变其运算内容。
讲这一段,就是要明确,在计算机中,准确的说是CPU中,程序和数据都是存储在计算机的内存或者硬盘中的,要使用时,都是要经过寻址来找出来加载到CPU中的。内存只是更快的硬盘,以下将会使用内存纸袋存储,忽略内存到硬盘的换入换出。
内存地址本质上对应物理硬件上的地址引脚。使用内存地址访问物理存储天经地义,内存地址和物理地址一一对应,也是天经地义。内存地址就是物理地址,这就是“实模式”。
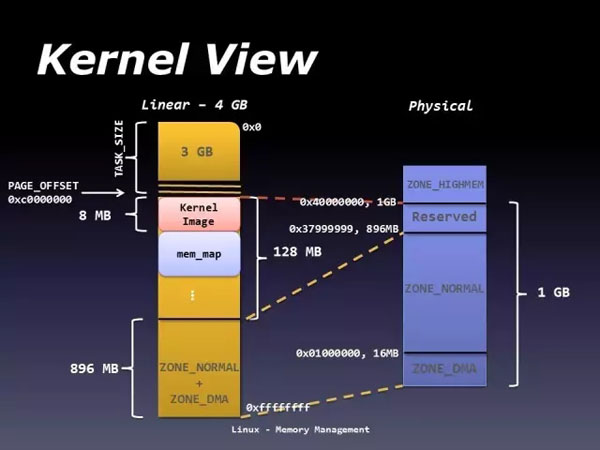
那是什么时候内存地址有了“逻辑地址”,“线性地址”,“虚拟地址”,“物理地址”等,这些称呼?
这一切都要从80286说起,Intel微处理器从这个版本开始引入了“保护模式”,也是就是内存地址的分段表示。顾名思义,这是为了内存保护的目的(还有就是分离用户空间和内核空间)。这样内存地址不再是物理地址了,而仅仅是一个偏移量了,原来的内存地址变成了逻辑地址,而这个偏移量则是“线性地址”或“虚拟地址”。要获得物理就需要在自己所在的段中去找(下面提到的段描述中有一个基地址)!为此,Intel引入了段描述符以及保护目的的鉴权属性,结合“程序存储”的概念,至少存在两种段描述符:代码段描述符和数据段描述符。如何找到内存地址所在的段描述符呢?Intel又引入段选择子,以及鉴权属性。这样使用段选择子就是可以找到段描述符,再使用原来的内存地址作为偏移量来找到真正的物理地址了。但是从实模式到保护模式,只有一个地址序号,哪里去找段选择子和段描述符呢?Intel引入了一些段寄存器来存储段选择子,当然至少是代码段寄存器和数据段寄存器。而内核在启动时会建立全局段描述符表,这样一切都解决了。为了加快段描述符表的访问(否则又是瓶颈),Intel又引入了不可编程的段描述符寄存器,随着段寄出器加载而加载。这就是鼎鼎大名的影子寄存器。
现在看来,这次失败的设计还是挺成功的。
Linux就直接绕过了分段机制。分段机制引入段选择子和段描述符把地址空间转换成偏移量,Linux通过为所有程序设置相同的段选择子和段描述符,把偏移量又转换成地址空间,一切又回到了原点。
看看分页是多么简单和优雅。以32位地址空间为例,分为三段(10,10,12),分别是作为页目录,页表和页框的索引,即可访问32G的物理内存。只需要存储页目录一个寄存器(cr3)即可。
在整个寻址的过程中,TLB缓存是至关主要的。TLB缓存内存线性地址到物理地址的直接映射,你说重要不重要?
TLB缓存还间接了影响了地址空间架构。我们知道Linux环境下32位系统进程地址空间是4G,这4G地址空间用户态占3G,内核态占1G。并且用户态各个进程的地址空间是独立的,也就是每个进程都可以访问0到3G的进程地址空间。而内核态的进程地址空间是所有进程共享的,即所有进程共用1个的地址空间。(更准确的说法是把内核地址空间映射到所有进程的地址空间)。内核为什么这么设计呢?为什么要划分用户空间和内核空间呢?答案就在TLB 缓存:因为在内核空间进入/退出时,刷新整个TLB的代价太高了。
- In the i386 arch, for example, we choose to map the kernel into every process's VM space so that we don't have to pay the full TLB invalidation costs for kernel entry/exit. This means the available virtual memory space (4GiB on i386) has to be divided between user and kernel space.
和TLB缓存相关还有一个重要的概念是hugepage。hugepage支持建立在大多数现代处理器架构提供的多页大小支持之上。例如,x86 CPU通常支持4K和2M(1G,如果架构支持)页面大小,ia64 架构支持多页大小4K,8K,64K,256K,1M,4M,16M,256M以及ppc64支持4K和16M。随着越来越大的物理存储器(几GB)更容易获得,TLB的优化更为关键。
TLB 驻留在CPU的1级cache里,是芯片访问最快的缓存,一般只能容纳100多条页表项,如果采用hugepage,则可以极大减少 TLB cache miss 导致的开销:TLB***,立即就获取到物理地址,如果不***,需要查 rc3->进程页目录表pgd->进程页中间表pmd->进程页框->物理内存,如果这中间pmd或者页框被虚拟内存系统替换到交互区,则还需要交互区load回内存。。总之,TLB cache miss是性能大杀手,而采用hugepage可以有效降低TLB cache miss。
一旦大量的页面被预分配给内核作为hugepage的页面池,这些页面将在内核中保留,不能用于其他目的。内核使用名字为“hugetlbfs” 的文件系统管理这些页面池。当支持多个hugepage大小时,/proc/sys/vm/nr_hugepages指示预先分配的大量页面的默认大小的当前数量。因此,可以使用以下命令来动态分配/取消分配默认大小的持续hugepage:
echo 20 > /proc/sys/vm/nr_hugepages
该命令将尝试将hugepage页面池中的默认大小的hugepage的数量调整为20 ,根据需要分配或释放hugepage。
/proc/meminfo文件提供有关内核hugepage池中持久hugetlb页面总数的信息。它还显示有关免费,预留和剩余hugepage数量以及默认页面大小的信息。“cat /proc/meminfo”的输出将包括以下行:
- .....
- HugePages_Total: vvv
- HugePages_Free: www
- HugePages_Rsvd: xxx
- HugePages_Surp: yyy
- Hugepagesize: zzz kB
其中: HugePages_Total是hugepage页面池的大小。 HugePages_Free是池中尚未分配的hugepage数。 HugePages_Rsvd是“保留” 的缩写,是从池中分配的承诺的hugepage的数量,但尚未分配。保留hugepage保证应用程序能够在故障时间从hugepage页面池中分配一个hugepage。 HugePages_Surp是“剩余”的缩写,是 /proc/sys/vm/nr_hugepages中的值之上的hugepage数。剩余hugepage的***数量由/proc/sys/vm/nr_overcommit_hugepages控制。
由于内核1G地址空间的限制,对于高端内存(物理地址空间大于虚拟地址空间的情况),内核无法同时映射所有物理内存,这意味着当使用这些内存时,内核使用临时映射。
说到高端内存,不禁想起了物理地址扩展。处理器所支持的RAM容量受链接到地址总线上的地址管脚数限制。早起Intel处理器从80386到Pentium使用32位物理地址。从理论上讲,这样的系统上可以安装高达4GB的RAM,而实际上,由于用户进程线性地址空间的需要,内核不能直接对1GB以上的RAM进行寻址。然而,大型服务器需要大于4GB的RAM来同时运行上千的进程,实际上我们现在的很多计算机的RAM都可能超过这个量级。Intel通过在它的处理器上把管脚数从32增加到36已经满足了这些需求。从Pentium Pro开始,Intel所有的处理器现在的寻址能力达2^36=64GB.不过,只有引入一种新的分页机制把32位线性地址转换为36位物理地址才能使用所增加的物理地址。显然,PAE并没有扩大进程的线性地址空间,因为它只能处理物理地址,此外,只有内核能够修改进程的页表,所以用户态下运行的进程不能使用大于4GB的物理地址空间。另一方面,PAE允许内核使用高达64GB的RAM,从而显著增加了系统中的进程数量。
【本文是51CTO专栏作者石头的原创文章,转载请通过作者微信公众号补天遗石(butianys)获取授权】
戳这里,看该作者更多好文